
Data Pipeline

Data Pipeline
DataPipeline, affiliated to Beijing Zhufeng Technology Co., Ltd., is an enterprise-level batch-stream integrated data fusion product, solution and service provider. The company adheres to the mission of “connecting all data, applications and devices” and is committed to “becoming a world-class China Data Middleware Vendors”. DataPipeline assists users to build business goal-oriented data links through a variety of real-time data technologies. The product supports a wide range of data node types, and can quickly customize, deploy, and execute data tasks on demand. It can realize data processing from traditional data processing to real-time data applications. Various scenarios.
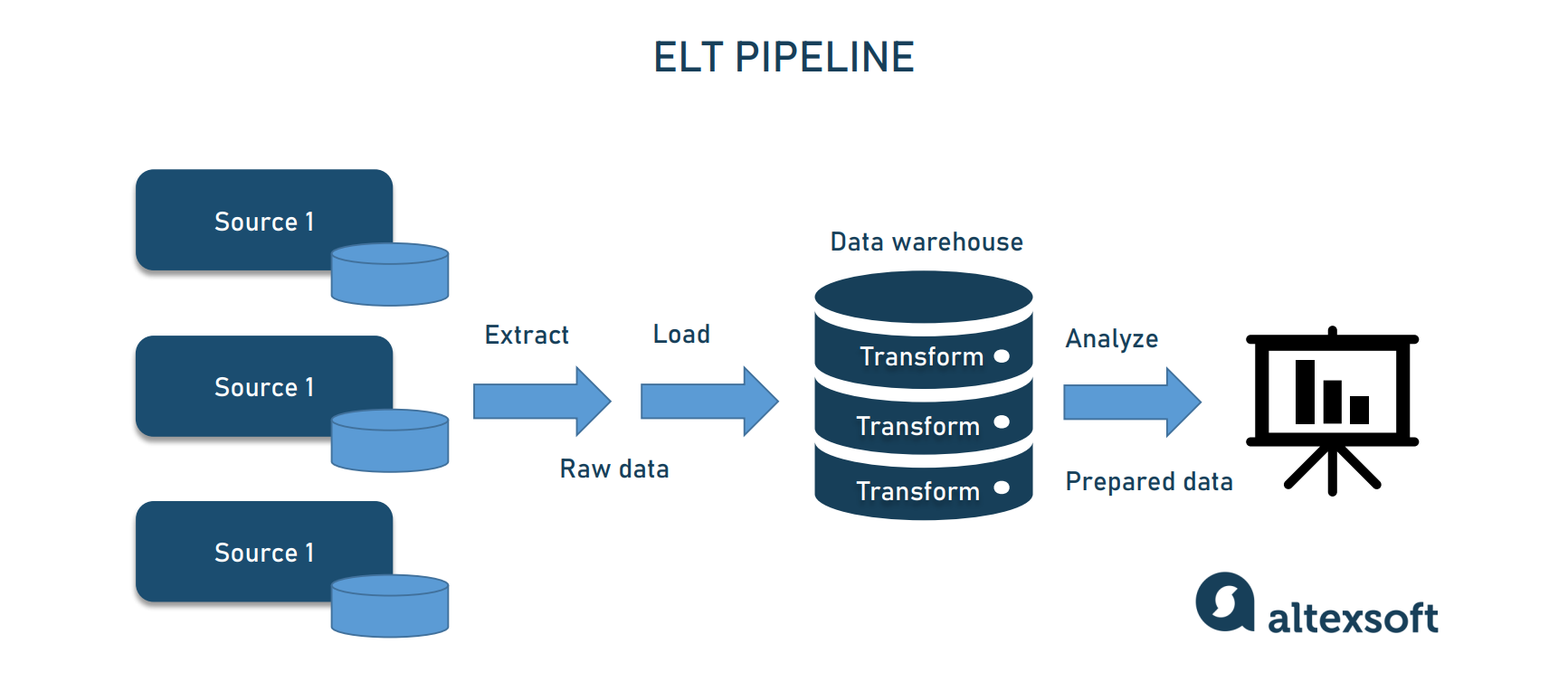 A data pipeline is a series of data processing steps. If the data is not currently loaded into the data platform, then it is ingested at the beginning of the pipeline. Then there are a series of steps in which each step delivers an output that is the input to the next step. This continues until the pipeline is complete. In some cases, independent steps may be run in parallel.
A data pipeline is a series of data processing steps. If the data is not currently loaded into the data platform, then it is ingested at the beginning of the pipeline. Then there are a series of steps in which each step delivers an output that is the input to the next step. This continues until the pipeline is complete. In some cases, independent steps may be run in parallel.
Data pipelines consist of three key elements: a source, a processing step or steps, and a destination. In some data pipelines, the destination may be called a sink. Data pipelines enable the flow of data from an application to a data warehouse, from a data lake to an analytics database, or into a payment processing system, for example. Data pipelines also may have the same source and sink, such that the pipeline is purely about modifying the data set. Any time data is processed between point A and point B (or points B, C, and D), there is a data pipeline between those points.
Data Pipeline Considerations
Data pipeline architectures require many considerations. For example, does your pipeline need to handle streaming data? What rate of data do you expect? How much and what types of processing need to happen in the data pipeline? Is the data being generated in the cloud or on-premises, and where does it need to go? Do you plan to build the pipeline with microservices? Are there specific technologies in which your team is already well-versed in programming and maintaining?
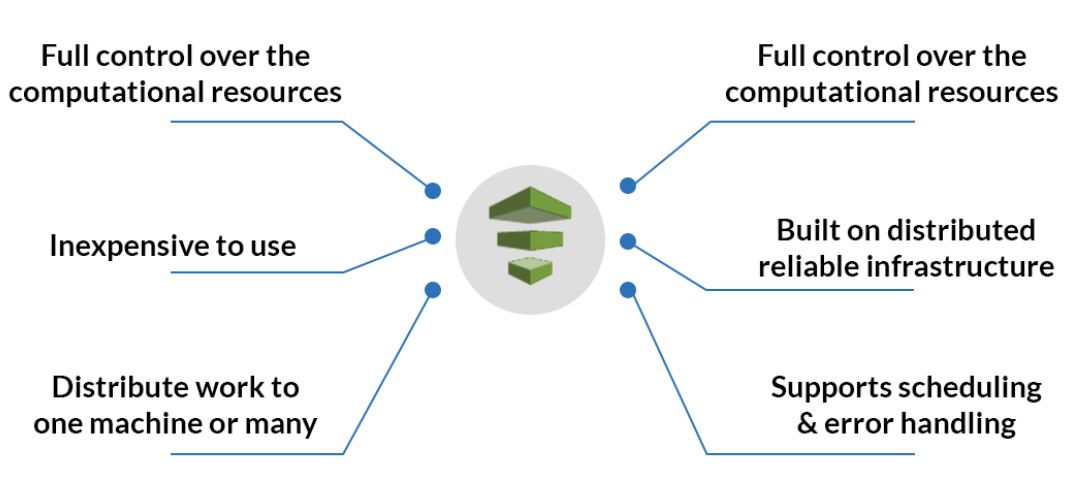
Types of data pipelines
There are two main types of data pipelines, which are batch processing and streaming data.
The development of batch processing was critical step in building data infrastructures that were reliable and scalable. In 2004, MapReduce, a batch processing algorithm, was patented and then subsequently integrated in open-source systems, like Hadoop, CouchDB, and MongoDB.
As the name implies, batch processing loads “batches” of data into a repository during set time intervals, which are typically scheduled during off-peak business hours. This way, other workloads aren’t impacted as batch processing jobs tend to work with large volumes of data, which can tax the overall system. Batch processing is usually the optimal data pipeline when there isn’t an immediate need to analyze a specific dataset (e.g. monthly accounting), and it is more associated with the ETL data integration process, which stands for “extract, transform, and load.”
Batch processing jobs form a workflow of sequenced commands, where the output of one command becomes the input of the next command. For example, one command may kick off data ingestion, the next command may trigger filtering of specific columns, and the subsequent command may handle aggregation. This series of commands will continue until the data is completely transformed and written into data repository.
Unlike batching processing, streaming data is leveraged when it is required for data to be continuously updated. For example, apps or point of sale systems need real-time data to update inventory and sales history of their products; that way, sellers can inform consumers if a product is in stock or not. A single action, like a product sale, is considered an “event”, and related events, such as adding an item to checkout, are typically grouped together as a “topic” or “stream.” These events are then transported via messaging systems or message brokers, such as the open-source offering, Apache Kafka.
Since data events are processed shortly after occurring, streaming processing systems have lower latency than batch systems, but aren’t considered as reliable as batch processing systems as messages can be unintentionally dropped or spend a long time in queue. Message brokers help to address this concern through acknowledgements, where a consumer confirms processing of the message to the broker to remove it from the queue.
Data pipeline architecture
Three core steps make up the architecture of a data pipeline.
1. Data ingestion: Data is collected from various data sources, which includes various data structures (i.e. structured and unstructured data). Within streaming data, these raw data sources are typically known as producers, publishers, or senders. While businesses can choose to extract data only when they are ready to process it, it’s a better practice to land the raw data within a cloud data warehouse provider first. This way, the business can update any historical data if they need to make adjustments to data processing jobs.
2. Data Transformation: During this step, a series of jobs are executed to process data into the format required by the destination data repository. These jobs embed automation and governance for repetitive workstreams, like business reporting, ensuring that data is cleansed and transformed consistently. For example, a data stream may come in a nested JSON format, and the data transformation stage will aim to unroll that JSON to extract the key fields for analysis.
3. Data Storage: The transformed data is then stored within a data repository, where it can be exposed to various stakeholders. Within streaming data, this transformed data are typically known as consumers, subscribers, or recipients.
Use cases of data pipelines
As big data continues to grow, data management becomes an ever-increasing priority. While data pipelines serve various functions, the following are three broad applications of them within business:
• Exploratory data analysis: Exploratory data analysis (EDA) is used by data scientists to analyze and investigate data sets and summarize their main characteristics, often employing data visualization methods. It helps determine how best to manipulate data sources to get the answers you need, making it easier for data scientists to discover patterns, spot anomalies, test a hypothesis, or check assumptions.
• Data visualizations: Data visualizations represent data via common graphics, such as charts, plots, infographics, and even animations. These visual displays of information communicate complex data relationships and data-driven insights in a way that is easy to understand.
• Machine learning: Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy. Through the use of statistical methods, algorithms are trained to make classifications or predictions, uncovering key insights within data mining projects.
Pros & Cons
Pros:
- Supports the majority of AWS databases with, an easy-to-use control interface with predefined templates.
- To only create resources and clusters when necessary.
- The ability to schedule jobs just during certain times.
- Protection for data both at rest and while in motion. AWS’s access control mechanism allows fine-grained control over who can use what.
- Users are relieved of all tasks relating to system stability and recovery thanks to fault-tolerant architecture.
Cons:
- It is built for AWS services, or the AWS world, and hence works well with all of the AWS parts. If you require data from many outside services, Pipeline Data aws is not the best choice.
- When managing numerous installations and configurations on the compute resources while working with data pipelines, might become daunting.
- To a beginner, the data pipeline’s way of representing preconditions and branching logic may appear complex, and to be honest, there are other tools available that help to accomplish complex chains more easily. A framework like Airflow is an example.
Data Pipeline pricing
Data Factory Pipeline Orchestration and Execution
Pipelines are control flows of discrete steps referred to as activities. You pay for data pipeline orchestration by activity run and activity execution by integration runtime hours. The integration runtime, which is serverless in Azure and self-hosted in hybrid scenarios, provides the compute resources used to execute the activities in a pipeline. Integration runtime charges are prorated by the minute and rounded up.
For example, the Azure Data Factory copy activity can move data across various data stores in a secure, reliable, performant and scalable way. As data volume or throughput needs grow, the integration runtime can scale out to meet those needs.
| Type | Azure Integration Runtime Price | Azure Managed VNET Integration Runtime Price | Self-Hosted Integration Runtime Price |
|---|---|---|---|
| Orchestration1 | $1 per 1,000 runs | $1 per 1,000 runs | $1.50 per 1,000 runs |
| Data movement Activity2 | $0.25/DIU-hour | $0.25/DIU-hour | $0.10/hour |
| Pipeline Activity3 | $0.005/hour | $1/hour
(Up to 50 concurrent pipeline activities) |
$0.002/hour |
| External Pipeline Activity4 | $0.00025/hour | $1/hour(Up to 800 concurrent pipeline activities) | $0.0001/hour |

